|
Shalom everyone. Since we just celebrated Shavuot (Pentecost) I thought I would post a short study I did on the omer counting and the yovel (jubilee) counting. Leading up to Shavuot this just popped into my head and I had to get it down on paper. I haven't dipped my toe in the "what year is the sh'mita year" controversy, but this just came to me. My typical response is that depending on who you ask, every year can be the sh'mita year, but I had a bit of a revelation and this is what came of it. Take it with a grain of salt. The Shavuot and yovel cycles are both cycles of 49+1 and they should also match up in how they are counted. For Shavuot we start the counting after the Shabbat during the feast of unleavened bread. We count 6 days and then the first of 7 Sabbaths comes. Continuing the counting we complete 7 Sabbath cycles of 7 days each to come to 49 days (7x7=49) and on the morrow after the seventh Sabbath we celebrate the feast of Shavuot on the 50th day. This is all in Leviticus chapter 23. This 50th day happens to be the 1st day of a new counting of 7 for the following week. So that there are only 5 working days that particular week until the next Shabbat. The yovel year and sh'mita cycle should be counted exactly the same. Counting 6 years and then the first of 7 land Sabbaths (sh'mita years) comes. Continuing the counting we complete 7 sh'mita cycles of 7 years each to come to 49 years (7x7=49) and on the year after the 7th sh'mita year we celebrate the yovel on the 50th year. Just like the Shavuot cycle, this 50th year happens to be the 1st year of a new counting of 7 for the following sh'mita cycle. So that there are only 5 years to work the land that particular sh'mita cycle until the next sh'mita year. See the chart labeled "Shavuot / Yovel Cycle (days and years)" below. 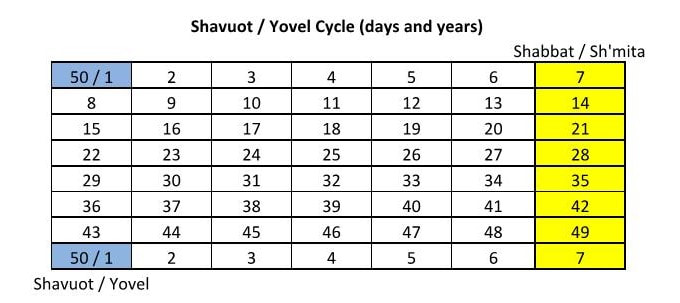 So the revelation was that the 50th year and the 1st year are the same. That would mean that the yovel cycle would be every 49 years and not every 50 years as I previously believed. In the country of Israel they began the counting of the sh'mita years in 1945. Some interesting things happened that year, particularly important to this discussion is the defeat of Germany and the end of WW2. If that is not a year to celebrate a jubilee I don't know what is. So I am making some big assumptions here, but for arguments sake, let's assume that the new beginning of the sh'mita cycle after almost 2,000 years is in fact the yovel year. That would make 1994 and 2043 yovel years as well. It is interesting to note that the sh'mita cycle in Israel is an unending cycle of sevens and they have not intercalated a 50th year as the yovel year. They do not believe they can fulfill the yovel until all of Israel is under their control. 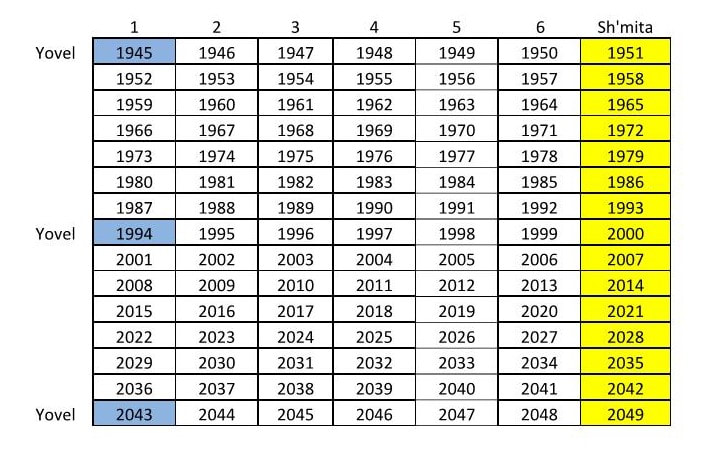 The thing that intrigued me the most was: does this line up with a certain historical data point I am aware of? The 2nd Temple was destroyed in 70 CE and the Talmud records that the destruction of the Temple was in the going out of the sh'mita year, meaning the year after a sh'mita year. Using the table below labeled "Yovel Years" we can see that if my above assumptions are correct, 83 CE was a yovel year meaning 82 CE was a sh'mita year. Counting back 14 years or 2 cycles of sh'mita years we can see that 68 CE was a sh'mita year. Traditionally sh'mita years start in the fall at Yom Teruah. So this means that fall 68 CE to fall 69 CE was a sh'mita year and that fall 69 CE to fall of 70 CE was the year after the sh'mita. The Temple was destroyed on the 9th of Av in 70 CE, this matches up perfectly. 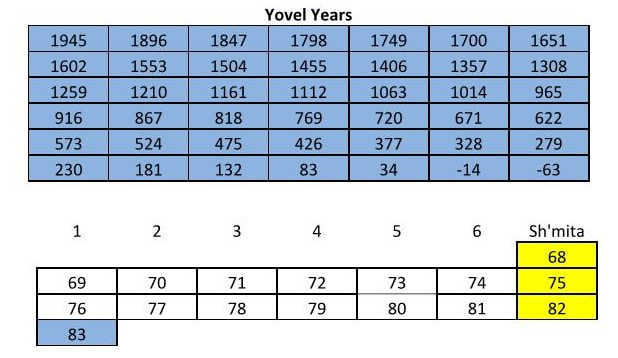 So like I said, take it with a grain of salt. There are a lot of assumptions there including with the way Shavuot is calculated, when the yovel year count starts, and what year the Temple was destroyed. But it just kind of hit me and I had to write it down and when I did the math it all worked out. Fun with math, something to think about. Shalom.
1 Comment
|
Archives
January 2024
Categories
All
|
 RSS Feed
RSS Feed